Понадобилось мне получать с Хабра ленту комментариев пользователя в каком-то удобном виде, чтобы не заходить периодически на сайт для проверки её обновления. Очевидное решение — RSS.
В базе Хабр позволяет подписаться на профиль пользователя, или, по RSS, на ленту его публикаций. А вот для комментариев подобной возможности не предусмотрено (сама лента комментариев имеет вид https://habr.com/ru/users/user-name/comments/).
Первая мысль — воспользоваться Yahoo Pipes, ведь когда-то уже использовал его для решения подобных задач. Увы — оказалось, что сервис давно закрыт. Помолчим минуту (он был хорош!) и рассмотрим доступные альтернативы.
Интернет предлагает несколько бесплатных (или имеющих бесплатные тарифные планы) вариантов, например:
- IFTTT — слишком абстрактно для моей задачи (первым шагом надо выбрать сервис, для которого у них есть готовые наборы правил обработки), плюс сразу предлагают привязать карту (для активации триала, хотя на стартовой странице обозначен и free plan). И свой триггер можно добавить только к сервису, с которым у IFTTT уже есть интеграция.
- pipe2py — предлагается разворачивать в Google App Engine, для чего нужно привязать карту, а сделать это в данный момент непросто. Слишком сложно для «просто попробовать и сравнить».
- Zapier — идеалогически похож на IFTTT — тоже надо выбирать готовое «приложение», которое уже есть в сервисе. Это не решение моей задачи.
- dlvr.it — тут всё понятно из их самопрезентации — Automate Social Media Posting — полностью мимо.
- Huginn — наконец — наш сегодняшний герой. Автономный (поддерживает локальное развертывание), гибкий (даже готовых обработчиков хватит для многого), скромный (в части интерфейса по сравнению с вышеперечисленными). Надо пробовать!
Сразу отмечу, что ни одно из приведённых решений (даже Huginn) не является аналогом Pipes, который был удобен своей возможностью комбинировать «блочную сборку» с тонкой настройкой алгоритма работы блока (если это требовалось). Однако — пора познакомиться с Huginn поближе.
Первое знакомство с Huginn
Установка
Самый простой вариант развертывания Huginn с целью ознакомления — использование готового docker-контейнера. Исчерпывающая инструкция приводится на соответствующей справочной странице, добавлю к ней пару пару моментов, касающихся вариантов развертывания контейнера.
Локальный docker
При локальной установке имеет смысл примонтировать хранилище в отдельный том (или каталог в хост-системе), который нужно предварительно создать: docker volume create huginn-mysql. А также — примонтировать .gitignore следующего содержания:
[safe]
directory = /appчтобы избежать лишней «ругани» в логах (при развертывании контейнера идёт обновление сабмодулей из репозитория).
После чего можно создать контейнер (на первый раз — с перенаправлением вывода контейнера в консоль):
docker run -it -p 3000:3000 -v huginn-mysql:/var/lib/mysql \
--mount type=bind,source="${HOME}"/dev/docker/gitconfig,target="/app/.gitconfig" \
--name huginn huginn/huginnи в дальнейшем запускать его через docker start huginn.
Внешний docker на GitHub
Среди доступных в настоящий момент сервисов, предлагающих бесплатные ресурсы для развертывания приложения, GitHub Godespaces — один из немногих. Что немаловажно — в нём можно просто развернуть контейнер docker, без необходимости писать сборочные скрипты.
Кстати, доступны весьма неплохие, для бесплатного предложения, варианты машин:
Достаточно в панели управления выбрать шаблон Blank, дождаться запуска сервиса, и в открывшейся консоли запустить докер: docker run -it -p 3000:3000 huginn/huginn.
Порты пробрасываются автоматически, после запуска приложение можно открыть в браузере (логин/пароль по умолчанию: admin / password). Чтобы приложение было доступно «извне», а не только внутри аккаунта github, нужно переставить порт на Public (правой кнопкой на Private -> Видимость порта -> Public).

Настало время перейти к главному — тому, ради чего всё затевалось — преобразованию страницы Хабра в RSS.
Парсинг сайта в Huginn
Простой вариант создания RSS
В простейшем случае — достаточно комбинации трёх агентов (так называются обработчики в Huginn), а именно:
- Website Agent — для получения исходных данных (страницы ленты) с сайта
- Event Formatting Agent — для подготовки (очистки) полученных данных
- Data Output Agent — вывод результата в RSS (xml) и json
но сначала стоит добавить новый сценарий, в котором эти агенты будут сгруппированы: Scenarios -> New scenario. На открывшейся после создания нового сценария странице можно смело жать New agent. Настройки агентов достаточно подробно документированы на странице их создания, подробно останавливаться не буду.
Website Agent
Выбрать тип Website Agent, дать ему произвольное название, добавить его к созданному сценарию, затем, в разделе Options, переключить вид настроек (Toggle View) и вставить туда код агента (не забудьте в ссылке поменять hbn3 на интересующего вас автора).
{
"url": "https://habr.com/ru/users/hbn3/comments/",
"mode": "on_change",
"expected_update_period_in_days": "30",
"extract": {
"url": {
"css": "a.tm-comment-footer__button",
"value": "@href"
},
"title": {
"css": "a.tm-user-comments__header-link",
"value": "string(.)"
},
"body_text": {
"css": "div.tm-comment__body-content",
"value": "./node()"
},
"publish_date": {
"css": "a.tm-article-comment__link",
"value": "string(.)"
},
"author": {
"css": "a.tm-user-info__username.router-link-active",
"value": "string(.)"
}
}
}Проверить работу агента можно, запустив режим Dry Run. Если всё нормально — откроется вкладка Events с результатами, в случае проблем — подробности будут на вкладке Log.
Event Formatting Agent
Аналогично — добавить новый агент соответствующего типа, вставить код, в качестве источника данных указать созданный на прошлом шаге Website Agent (выбрать по названию в выпадашке).
{
"instructions": {
"message": "<p>{{body_text}}<\/p>",
"published": {
"date": "{{pretty_date.date}}",
"time": "{{pretty_date.time}}",
"raw_date": "{{publish_date | lstrip | rstrip}}"
},
"author": "{{author | lstrip | rstrip}}",
"link": "https://habr.com{{url}}",
"title": "{{title}}"
},
"matchers": [
{
"path": "{{publish_date | lstrip | rstrip}}",
"regexp": "(?<date>\\d{2}\\.\\d{2}\\.\\d{4})\\s.\\s(?<time>\\d{2}:\\d{2})",
"to": "pretty_date"
}
],
"mode": "clean"
}Для проверки работы этого агента — перед запуском Dry Run необходимо однократно запустить (Run) агент предыдущего шага, чтобы сгенерировать подлежащие обработке события.
Data Output Agent
Наконец, последний в этой цепочке — Data Output Agent, предназначенный для генерации RSS/JSON фида. Создается тем же способом, источником данных для него служит Event Formatting Agent с прошлого шага. Код агента:
{
"secrets": [
"habr-ucf"
],
"expected_receive_period_in_days": "1",
"template": {
"title": "Habr comments feed",
"description": "Comments feed of Habr user",
"item": {
"title": "{{title}}",
"description": "{{message}}",
"link": "{{link}}",
"pubDate": "{{published.date}} {{published.time}}",
"dc:creator": "{{author}}"
},
"language": "ru"
},
"ns_media": "true"
}secrets здесь содержит уникальную часть url-адреса будущего фида.
Результат
Наконец — можно запустить Website Agent и дождаться прохождения событий по цепочке агентов (это происходит в пределах минуты-другой, также есть возможность вызвать принудительное распространение событий). В итоге должна получиться следующая связь из трёх агентов:
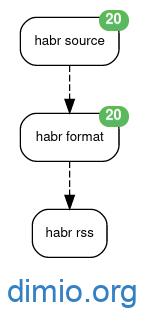
Из диаграммы видно, что из источника (Хабр) было отобрано на основе правил 20 записей, которые затем были отформатированы и трансформированы в ленту.
Адреса фидов можно найти на вкладке Summary агента Data Output Agent.
Если видимость проброшенного порта объявлена, как Public — на ленту можно подписаться, не логинясь в аккаунт Github.
Продвинутый вариант создания RSS
Чтение ленты комментариев одного пользователя — это уже неплохо. Но что делать, если есть потребность читать нескольких? Здесь также возможны варианты:
- Простой вариант — скопировать всю цепочку агентов. Можно даже в отдельный сценарий, ещё проще — экспортировать существующий сценарий, переименовать его и агенты (в полученном при экспорте файле), затем — импортировать обратно в Huginn. Поменять ссылку-источник на нужную, пользоваться. Минусы — игнорирование DRY, повышается нагрузка приложение. Ленты разных пользователей (источников) сливаются в одну общую, которой в дальнейшем неудобно пользоваться. Захламляется пространство сценариев. Плюсы — крайне просто реализуется, отключить ставшую ненужной ленту можно через управление сценарием.
- Сбалансированный вариант (на нём остановлюсь подробней) — создать источники данных для разных ссылок, после обработки — разделить поток на отдельные для каждого источника ленты . Минусы — тот же DRY, чуть сложней в реализации. Плюсы — при необходимости можно добавлять источники в виде
Website Agentпростым клонированием самого агента с подстановкой в ссылку имени интересующего пользователя. В отсутствие необходимости в источнике — можно просто отключить соответствующийWebsite Agent. - Экономичный вариант — использовать один общий
Website Agentдля нескольких ссылок. Минус этого варианта — для добавления/отключения источников надо или редактировать настройкиWebsite Agent, или выключать агенты-потребители ниже по цепочке (при этом сохранятся запросы уже не нужных страниц). Плюс — не приходится создавать «лишние» агенты, реализуется такой вариант несложно (на базе второго).
"url": [
"https://habr.com/ru/users/hbn3/comments/",
"https://habr.com/ru/users/AntonyN0p/comments/"
],Сбалансированный вариант
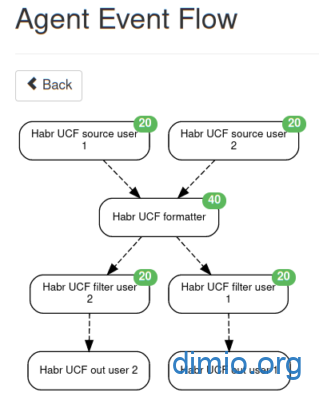
На время опытной эксплуатации (пока Huginn у меня работает в развёрнутом локально контейнере) я остановился на варианте 2. Подробно расписывать его реализацию не буду, скажу лишь, что в цепочку добавляются Trigger Agent для разбивки ленты на отдельные потоки по авторам. Схема, в этом случае, выглядит следующим образом:
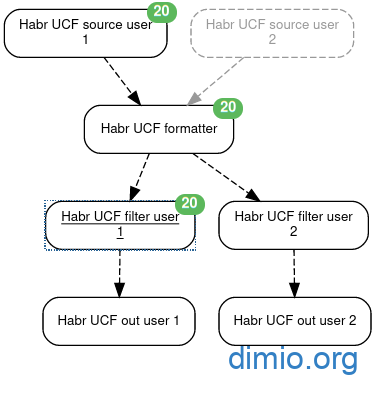
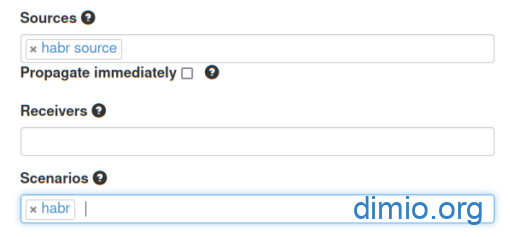
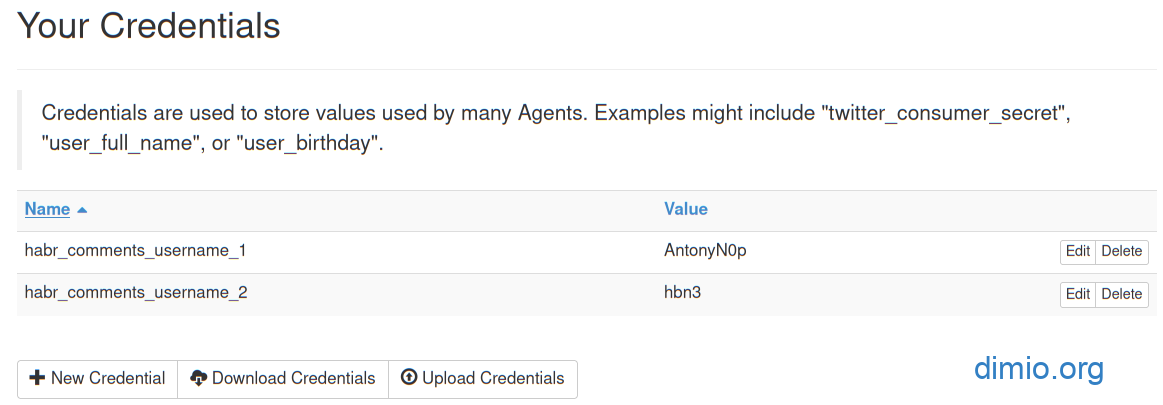
Готовый сценарий с набором агентов для второго варианта привожу в виде файла и в виде ссылки на Github. Имена целевых авторов хранятся в Credentials:
При развертывании Huginn на хостинге — планирую перейти на третий вариант формирования лент (с некоторыми доработками — чтобы список ссылок создавался на основе тех же Credentials), о чём незамедлительно напишу :). А пока — приятного (и полезного) оHuginnения!