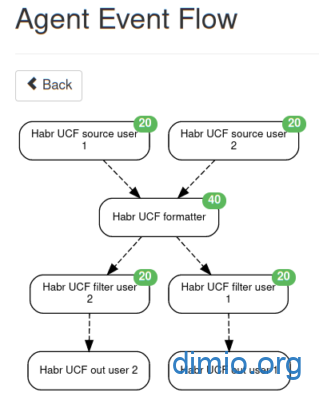
Понадобилось мне получать с Хабра ленту комментариев пользователя в каком-то удобном виде, чтобы не заходить периодически на сайт для проверки её обновления. Очевидное решение – RSS.
В базе Хабр позволяет подписаться на профиль пользователя, или, по RSS, на ленту его публикаций. А вот для комментариев подобной возможности не предусмотрено (сама лента комментариев имеет вид https://habr.com/ru/users/user-name/comments/).
Первая мысль – воспользоваться Yahoo Pipes, ведь когда-то уже использовал его для решения подобных задач. Увы – оказалось, что сервис давно закрыт. Помолчим минуту (он был хорош!) и рассмотрим доступные альтернативы.
Читать далее Huginn, Yahoo Pipes, Habr и фид ленты комментариев
